02 엘라스틱서치 기본

Elasticsearch는 Apache Lucene( 아파치 루씬 ) 기반의 Java 오픈소스 분산 검색 엔진입니다.
Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며,
방대한 양의 데이터를 신속하게, 거의 실시간( NRT, Near Real Time )으로 저장, 검색, 분석할 수 있습니다.
Elasticsearch는 검색을 위해 단독으로 사용되기도 하며,
ELK( Elasticsearch / Logstatsh / Kibana ) 스택으로 사용되기도 합니다.
ELK 스택이란 다음과 같습니다.
1. Logstash
다양한 소스( DB, csv파일 등 )의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달
2. Elasticsearch
Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득
3. Kibana
Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
Restful
데이터 CURD 작업은 HTTP Restful API를 통해 수행하며, 각각 다음과 같이 대응합니다.
| Data CRUD | Elasticsearch Restful |
| SELECT | GET |
| INSERT | PUT |
| UPDATE | POST |
| DELETE | DELETE |
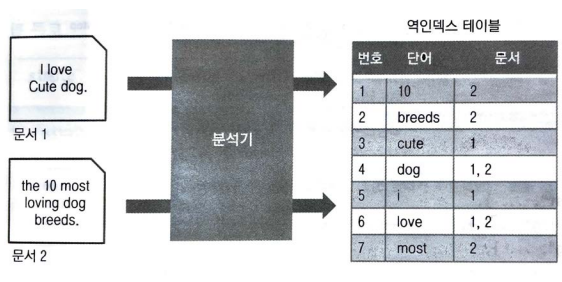
해당 문서를 분석기를 거치면 오른쪽과 같습니다.
the 10 most ...에서 the는 스톱 필터에 의해 역인덱스 테이블에 들어가지 않습니다~!
본격 분석하기!

POST _analyze 로 분석을 할 것인데
해당 문서에 stop 토큰 필터를 사용하여 분석하며 text에 적었던 문자열이 [most, loving, dog, breeds] 4개의 토큰으로 분리되었고,
'the', '10' 등은 스톱 분석기에 의해 토큰으로 지정되지 않았습니다.
※분석기는 반드시 하나의 토크나이저를 포함해야 합니다.
토크나이저는 문자열을 분리해 토큰화하는 역할을 합니다.
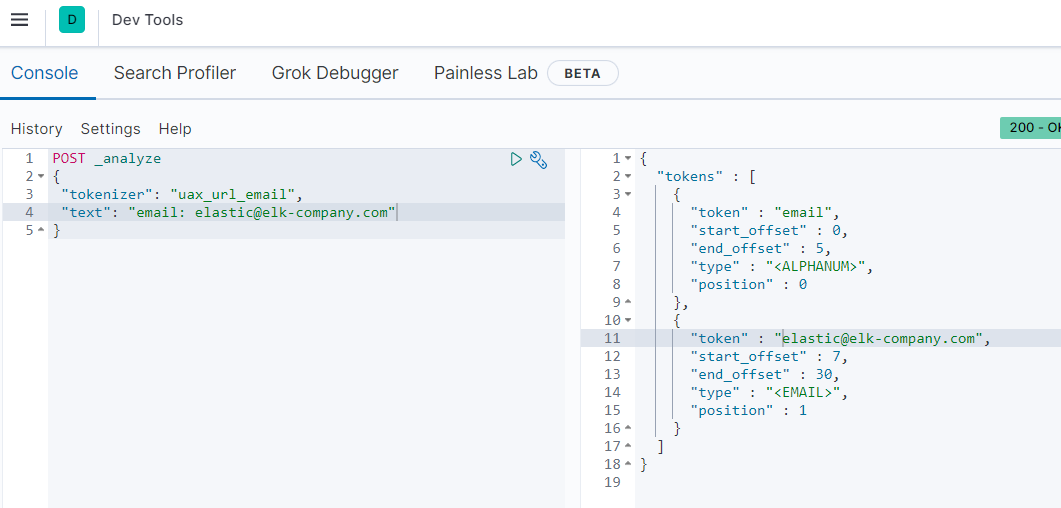
uax_url_email 토크나이저는 [email, elastic@elk-company.com]으로 토큰화하였습니다.
(1) 캐릭터 필터
토크나이저 전에 위치하여 문자들을 전처리하는 역할을 하는데,
HTML 문법을 제거/변경하거나 특정 문자가 왔을 때 다른 문자로 대체하는 일들을 합니다.
(2) 토큰 필터
토크나이저에 의해 토큰화되어 있는 문자들에 필터를 적용합니다.
예시)
customer_analyzer를 만듭니다.
PUT customer_analyzer
{
"settings": {
"analysis": {
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["lions"]
} 여기서 핵심은 지우는 단어를 lions으로 설정합니다.
analyzer 분석에서 필터에 my_stopwords를 넣습니다.
my_stopwords는 lions이 들어가 있죠?
실행하면 라이언은 빠지고(삭제) 나머지인 cat과 dog가 소문자로 바뀔 것입니다.
결과)

오늘도 수고하셨습니다!