엑셀 파일을 로그스테시, 키바나로 보내는 방법!
안녕하세요 jju_developer입니다.
드디어 파이널 프로젝트에 적용할 빅데이터! 시각화하는 방법을 하는 부분에 도달을 하였습니다.
👏🏻👏🏻👏🏻👏🏻박수 👏🏻👏🏻👏🏻👏🏻
이제, 시각화 하고자 하는 데이터가 엑셀 파일로 있습니다.
이것을 어떻게 키바나로 보내서 시각화를 해야 하는지 천천히 수업시간에 배운 내용을 활용하면서
적용을 해보도록 하겠습니다.
맥북에서는 엑셀 파일이 열리지 않기 때문에 Numbers 어플을 다운로드하여 줍니다.
Numbers에서 원하는 파일을 가공하고 해당 파일을 CSV로 변환하는 과정을 하겠습니다.
왜냐하면 키바나에서 파일을 업로드 할때에 CSV 파일로 업로드를 해야 하기 때문입니다.
Step 01. 파일을 CSV로 변환하라
여기서 주의사항 엑셀 파일의 헤더 제목은 삭제하셔야 합니다.
제목 즉, 항목 이름을 삭제하지 않으면 csv에서 해당 내용도 레코드로 보기 때문입니다.
이 부분을 없애고 나중에 파일 만들때 해당 제목 이름을 넣어 줄 예정입니다!
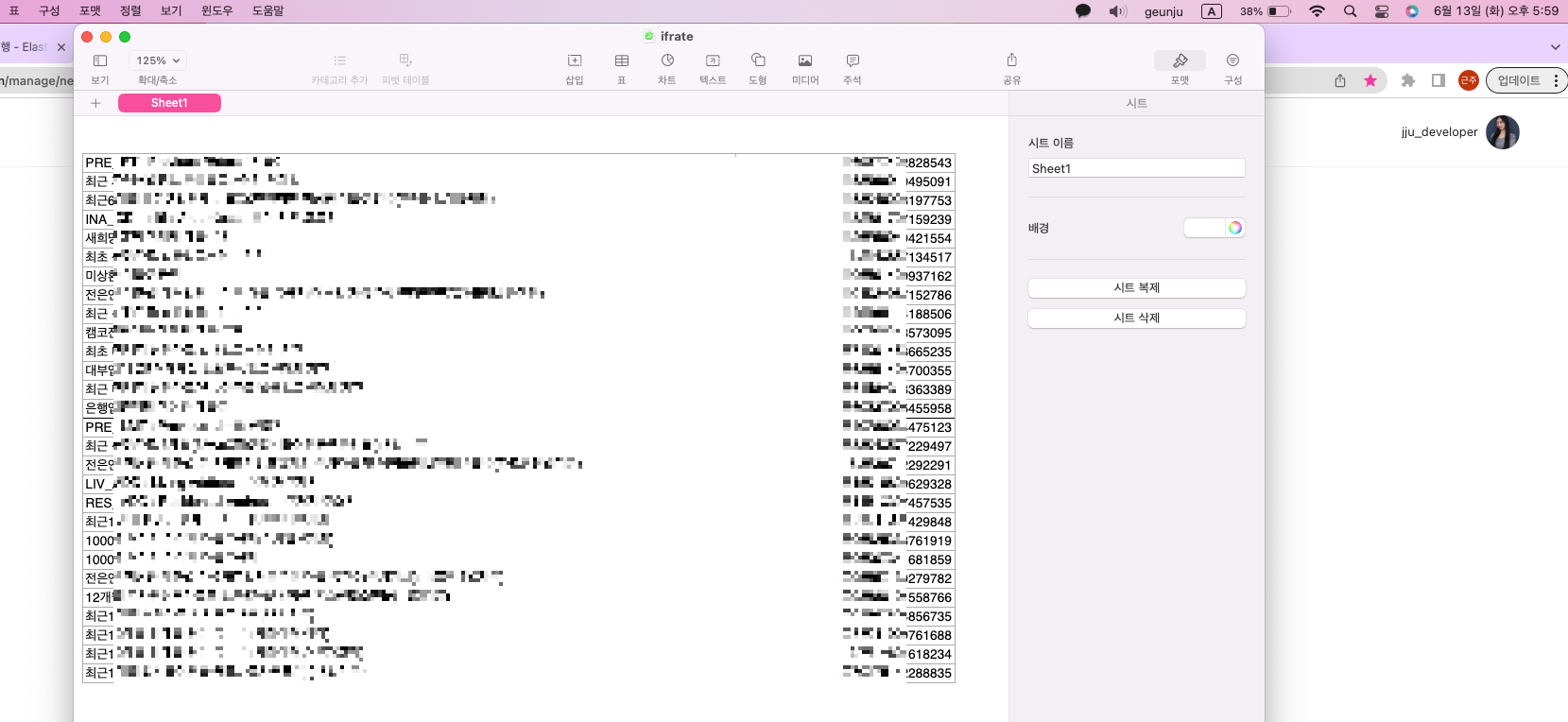
이렇게 원하고자 하는 데이터만 넣어주시고, 공유 눌러서 CSV로 파일을 변환하여 저장해 주세요~!
Step 02. 로그스테시 conf 파일을 만들어라!
logstash를 실행하려면 보통 logstash의 bin 폴더 안의 logstash를 실행을 하는데,
bin 폴더 말고 config 폴더에 들어가서 하나 파일을 만들어 주고 vscode로 열어주었습니다.
Logstash에 sampledata.conf파일을 생성하였습니다.
input {
file {
path => "/home/본인의 로컬의 절대 경로~/나의비밀파일의이름.csv"
start_position => "beginning"
}
}
filter {
csv {
columns => ["컬럼1", "컬럼2"]
separator => ","
}
mutate { convert => ["컬럼1", "string"] }
mutate { convert => ["컬럼2", "integer"] }
}
output {
elasticsearch {
action => "index"
hosts => ["localhost"]
index => "test"
}
stdout { }
}이렇게 이곳에서 아까 지웠던 칼럼의 이름을 넣어주어야 합니다!!!
저는 데이터 내용이 첫 번째 칼럼은 name 이고 두번째 컬럼은 rate이기 때문에
그렇게 수정하였습니다.
columns는 삭제했던 첫 행의 필드값을 순서대로 기재하며,
index는 Elasticsearch에 적재할 데이터의 index명을 기재합니다.
간단하게 test로 기재하였습니다.
Step 03. 터미널에서 명령어 실행!
1. elasticsearch를 실행하여 아래의 명령어를 실행합니다.
(저는 키바나에서 해당 명령어를 실행했네요,,,? 뭐지... 돌아가긴 했습니다...?😿 암튼 elasticsearch 터미널에서 하세요... )
curl -XPUT localhost:9200/test
위의 명령어는 elasticsearch에 test라는 이름의 index를 생성하는 명령어입니다.
2. 이후에 logstash 디렉토리 아래의 bin디렉토리에 들어가서 terminal을 실행하여 아래의 명령어를 실행합니다.
logstash -f /home/아까 작성한 logstash의 sampledata.conf경로/sampledata.conf
정상 실행이 되었다면 아래와 같이 json형식으로 csv의 내용이 출력됩니다.
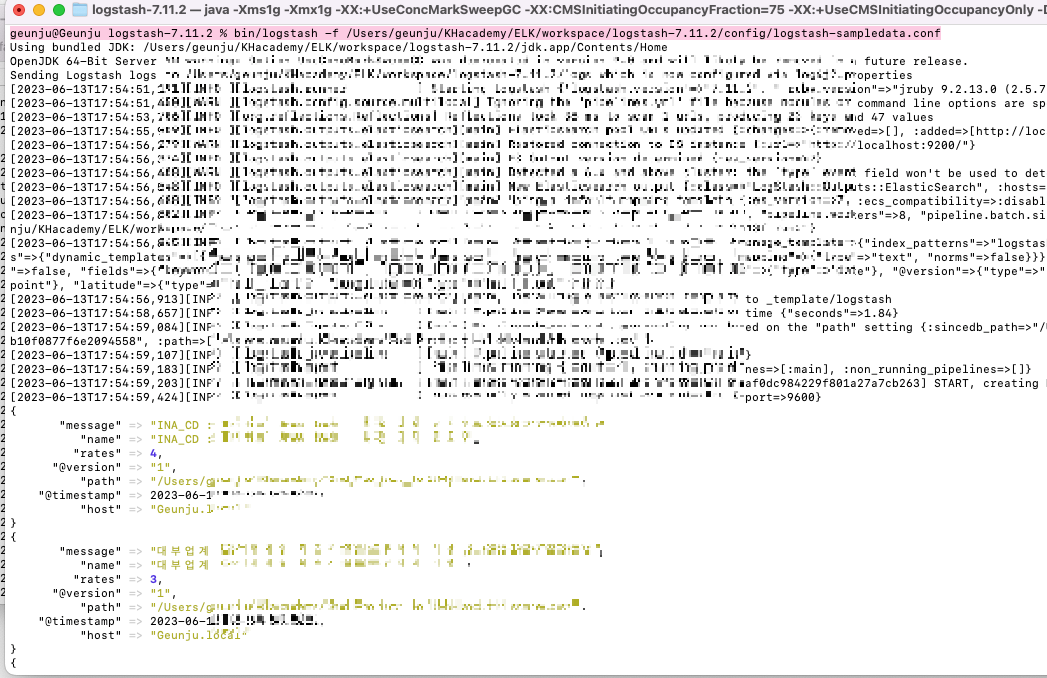
http://localhost:9200/인덱스이름!!!/_search?pretty
http://localhost:9200/test/_search?pretty
이렇게 브라우저에 검색을 해보겠습니다.
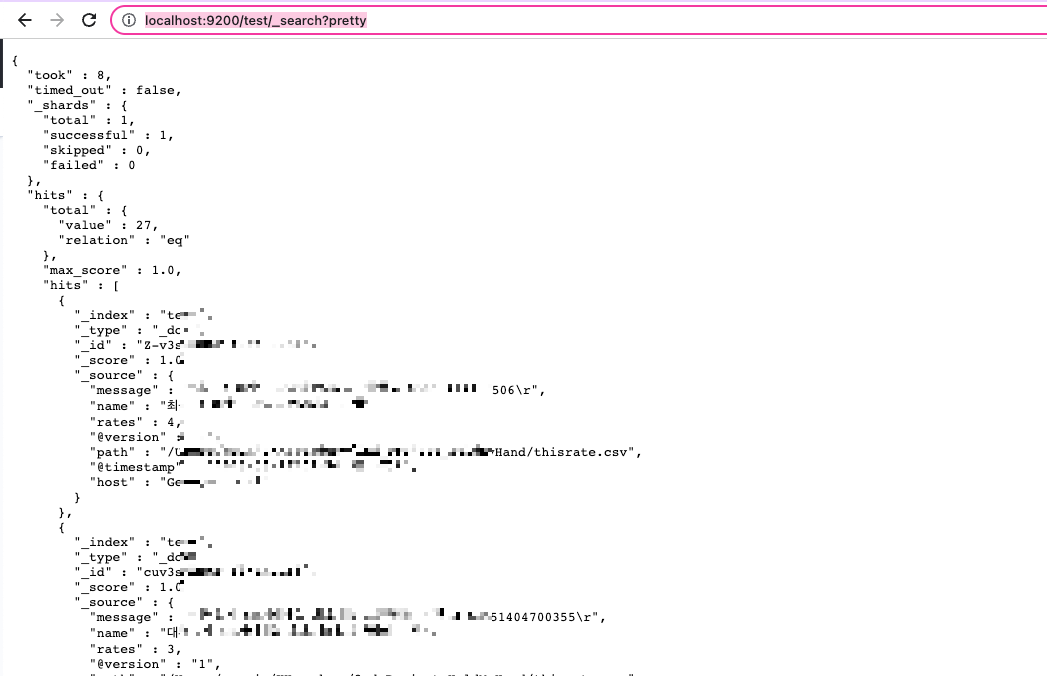
이렇게 27개의 레코드가 들어있는 것을 볼 수 있습니다!!
Step 04. 키바나에 파일 적용 / 인덱스 생성
자, 이제 수업 때 배운 내용 3번부터 적용하여해 보겠습니다.
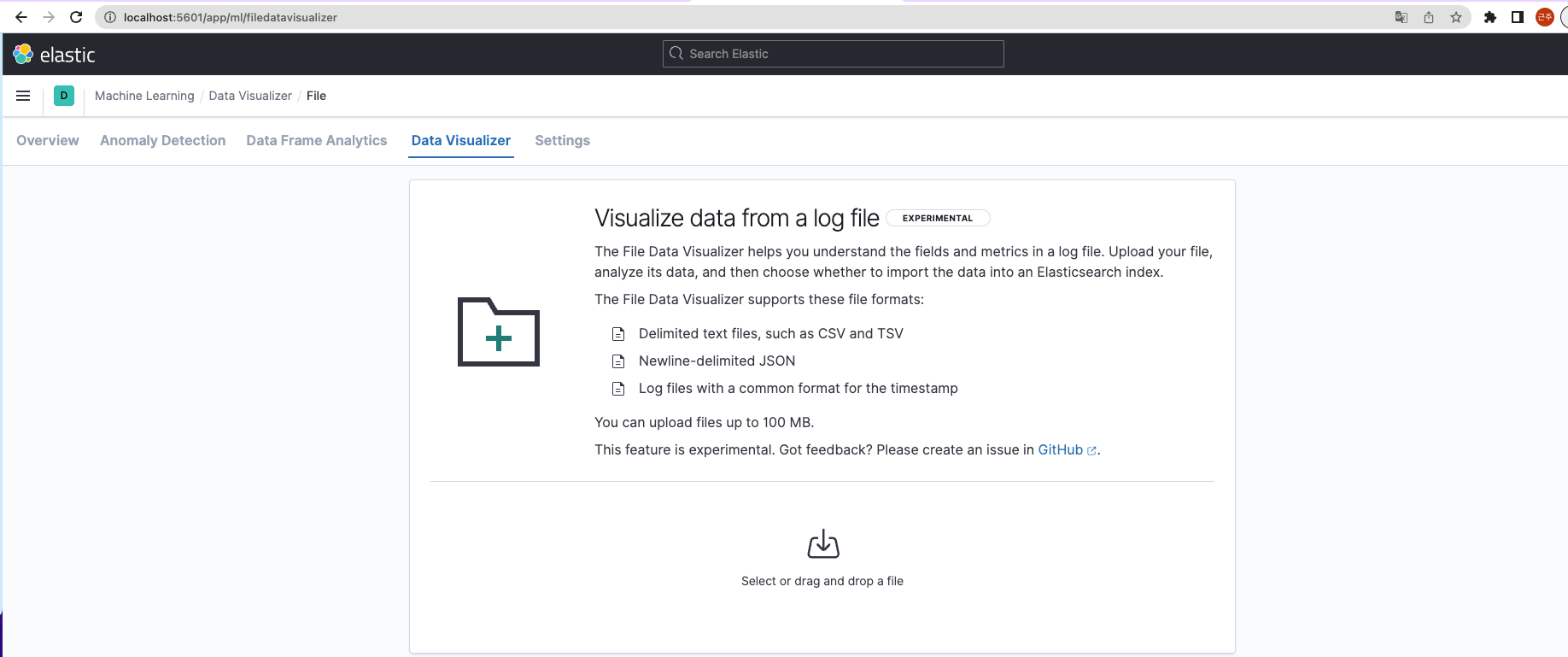
5601로 띄운 다음, 왼쪽 상단바의 머신러닝 클릭 -> 방금 만든 CSV 파일을 드롭해 줍니다.
파일을 확인하여 정상적임을 확인한 뒤, import를 눌러줍니다.
지난 시간에 했던 내용과 겹치기 때문에 중간중간 생략하여 빠르게 넘어가겠습니다.
(해당 블로그를 확인해 보세요! 캐글은 넘어가고 3번부터 적용!)
캐글 CSV 파일을 활용한 인덱스 작성
안녕하세요 jju_developer입니다. 이번시간에는 캐글 관련하여 배운 수업내용을 정리하여 공유드립니다. 정보통신기술 ICT의 발달로 매 순간 어마어마한 데이터가 쏟아져 나오고 있습니다. 종래의
jju240.tistory.com

index : credit_rate
Step 05. 인덱스 확인
devtool에서 무슨 인덱스가 있는지 확인
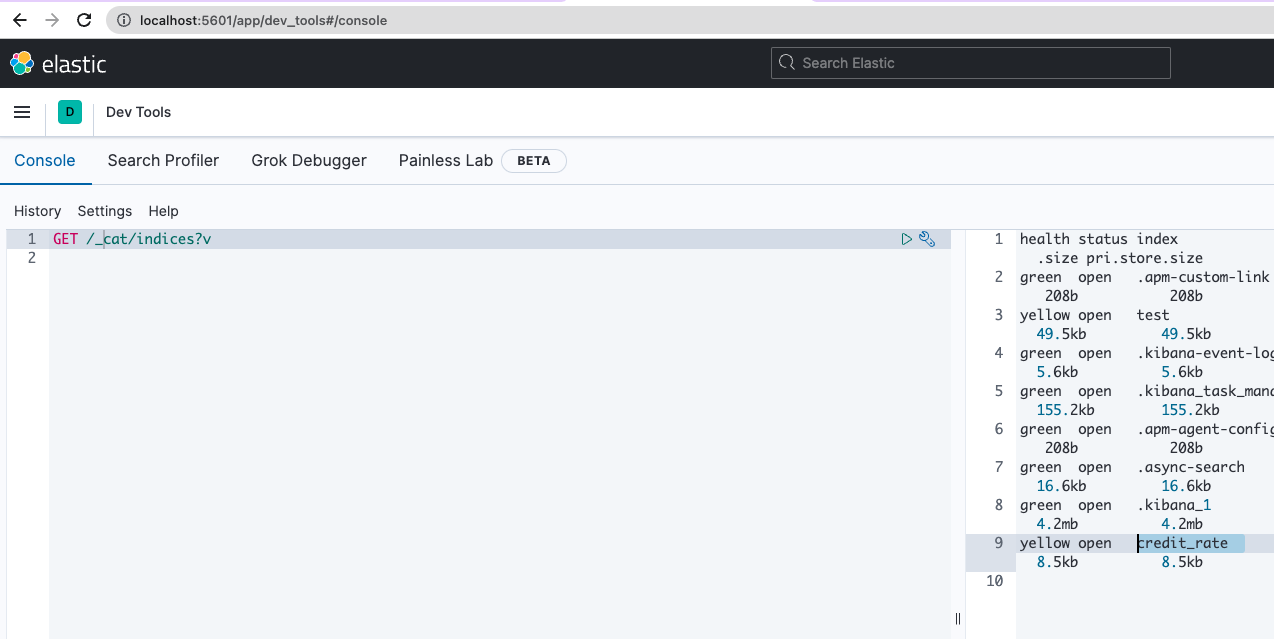
맨 아래에 만들었던 credit_rate이 있네요!
Step 06. 그래프 만들기!
어떤 그래프가 적합한지 결정을 해야 하는데... 무엇으로 하면 좋을지 생각을 해보았습니다.
▶️꺾은선 그래프 (Line Chart):
시간에 따른 변화를 표현하기에 적합합니다.
시계열 데이터의 추이나 변동을 시각적으로 파악할 수 있습니다.
연속적인 데이터 값을 보여줄 때 유용합니다.
데이터 간의 관계와 추세를 확인할 수 있습니다.
여러 개의 중요한 rate을 동시에 비교하고자 할 때 유용합니다.
▶️파이 차트 (Pie Chart):
전체 대비 각 항목의 비율을 보여주기에 적합합니다.
항목들 간의 상대적인 중요도를 시각적으로 비교할 수 있습니다.
주로 몇 가지 항목의 비율을 나타낼 때 사용합니다.
항목이 많아지면 파악하기 어려울 수 있습니다.
▶️막대그래프 (Bar Chart):
항목들 간의 상대적인 크기를 비교하기에 적합합니다.
각 항목의 크기를 직관적으로 파악할 수 있습니다.
여러 개의 중요한 rate을 동시에 비교하고자 할 때 유용합니다.
항목들이 범주 형태로 구분될 수 있습니다.
따라서, 중요한 rate을 나타내는 표 형식은 데이터의 특성과 비교하고자 하는 요소에 따라 다르며, 꺾은선 그래프는 시간에 따른 변화를 보여주고자 할 때, 파이 차트는 항목들의 상대적인 비율을 나타내고자 할 때, 막대그래프는 항목들 간의 크기를 비교하고자 할 때 적합합니다. 데이터의 구조와 시각화 목적을 고려하여 가장 적합한 그래프 형식을 선택하시면 됩니다.
저는 프로젝트에 사용될 데이터를 임시로 가져왔으며, 그냥 예시로 크기만 비교하였습니다.
Visualize에서 원하는 표 모양을 선택해서 update 하시면 됩니다!!!

오늘도 수고하셨습니다 ^^