빅데이터 엘라스틱 스택 수업내용 간략 정리본
정말 간단히 이해한 내용만!



다 다운받으면 됨
http://localhost:5601/app/home#/tutorial_directory/sampleData

총 3개의 샘플데이터가 있음
이미 깔려있음
일렉서치의 데이터베이스의 구조는 인덱스와 도큐먼트로 되어있다.
인덱스, 도큐먼트, 필드의 구조
• 인덱스는 도큐먼트를 저장하는 논리적 구분자이며, 도큐먼트는 실제 데이터를 저장하는 단위다.
• 엘라스틱을 이용해 시스템을 개발하면 하나의 프로젝트에서 하나의 클러스터를 생성한다.
그리고 클러스터 내부는 데이터 성격에 따라 여러 개의 인덱스를 생성한다.
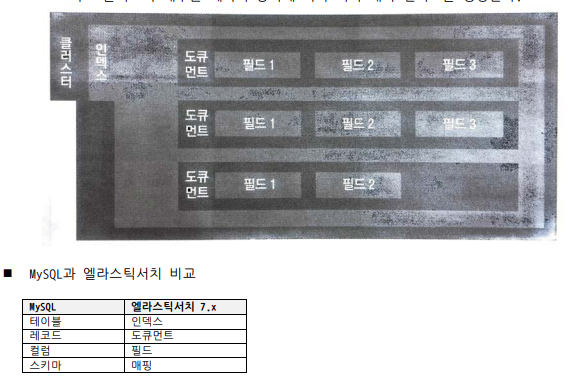
테이블을 엘라스틱 서치에서는 인덱스라고 하고,
(인덱스는 도큐먼트를 저장하는 논리적 단위로, 관계형 데이터베이스의 테이블과 유사한 개념이다)
하나의 긴 레코드(테이블 안의 데이터 집합)는 도큐먼트라고 하고
(도큐먼트는 엘라스틱서치에서 데이터가 저장되는 기본 단위로 JSON 형태이며, 하나의 도큐먼 트는 여러 필드(field)와 값(value)을 갖는다.)
레코드 안에 있는 필드들을 칼럼이죠 즉 여기서는 필드라고 그냥 함
그러면 이 도큐먼트를 CRUD를 어떻게 하냐면!
도큐먼트 CRUD 3.3.1
인덱스 생성/확인/삭제
도큐먼트는 반드시 하나의 인덱스에 포함되어야 한다.
그래서 도큐먼트 CRUD 동작을 하기 위 해서는 반드시 인덱스가 있어야 한다.
# 인덱스 생성 PUT index1 # 인덱스 조회 GET index1 # 인덱스 삭제 DELETE index1
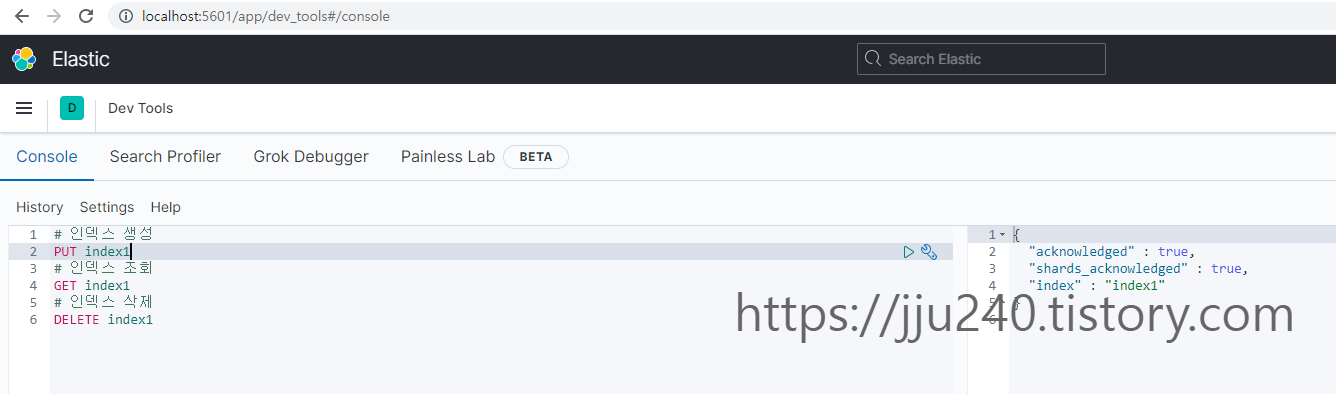
PUT index1
그다음

실행할 때에는 컨트롤 엔터 누르면 된다.
http://localhost:9200/index1

이거나 저거나 똑같은 건데 그냥 크롬에서 띄워본 것ㅋㅋ

이제 인덱스 삭제하고 다시 겟 인덱스 하면 에러남
다시 인덱스를 만들고
3.3.2 도큐먼트 생성
앞서 도큐먼트는 반드시 하나의 인덱스에 포함돼야 한다고 했다.
엘라스틱서치에서 도큐먼트를 인덱스에 포함시키는 것을 인덱싱(indexing)이라고 한다.
• 리스트 3.3을 요청하면 존재하지 않았던 index2라는 인덱스를 생성하면서 동시에 index2 인덱스에 도큐먼트를 인덱싱 한다.
• 1: index2는 인덱스 이름, _doc은 엔드포인트 구분을 위한 예약어, 숫자 1은 인덱싱할 도큐먼트의 고유 아이디다.
• 19,22,31: mappings에 age는 long 타입, gender와 name은 text 타입으로 필드가 지정되었다. 데이터 타입을 지정하지 않아도 엘라스틱서치는 도큐먼트의 필드와 값을 보고 자 동으로 지정하는데, 이런 기능을 다이내믹 매핑이라고 한다.
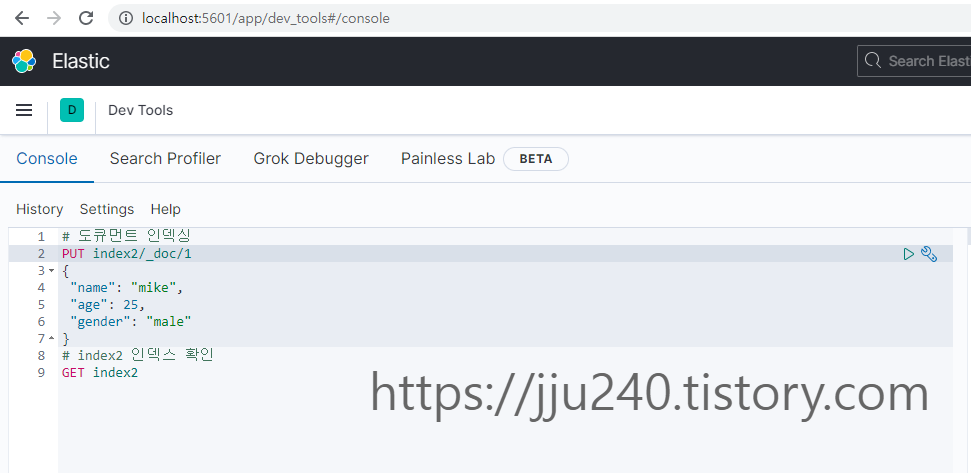
# 도큐먼트 인덱싱
PUT index2/_doc/1
{
"name": "mike",
"age": 25,
"gender": "male"
}
# index2 인덱스 확인
GET index2
도큐먼트를 만들어본다

인덱스가 1만 있었는데 도큐먼트 인덱싱으로 인덱스 2 가 만들어졌고
아래 겟 인덱스 2 하면 맵핑된 거 나옴
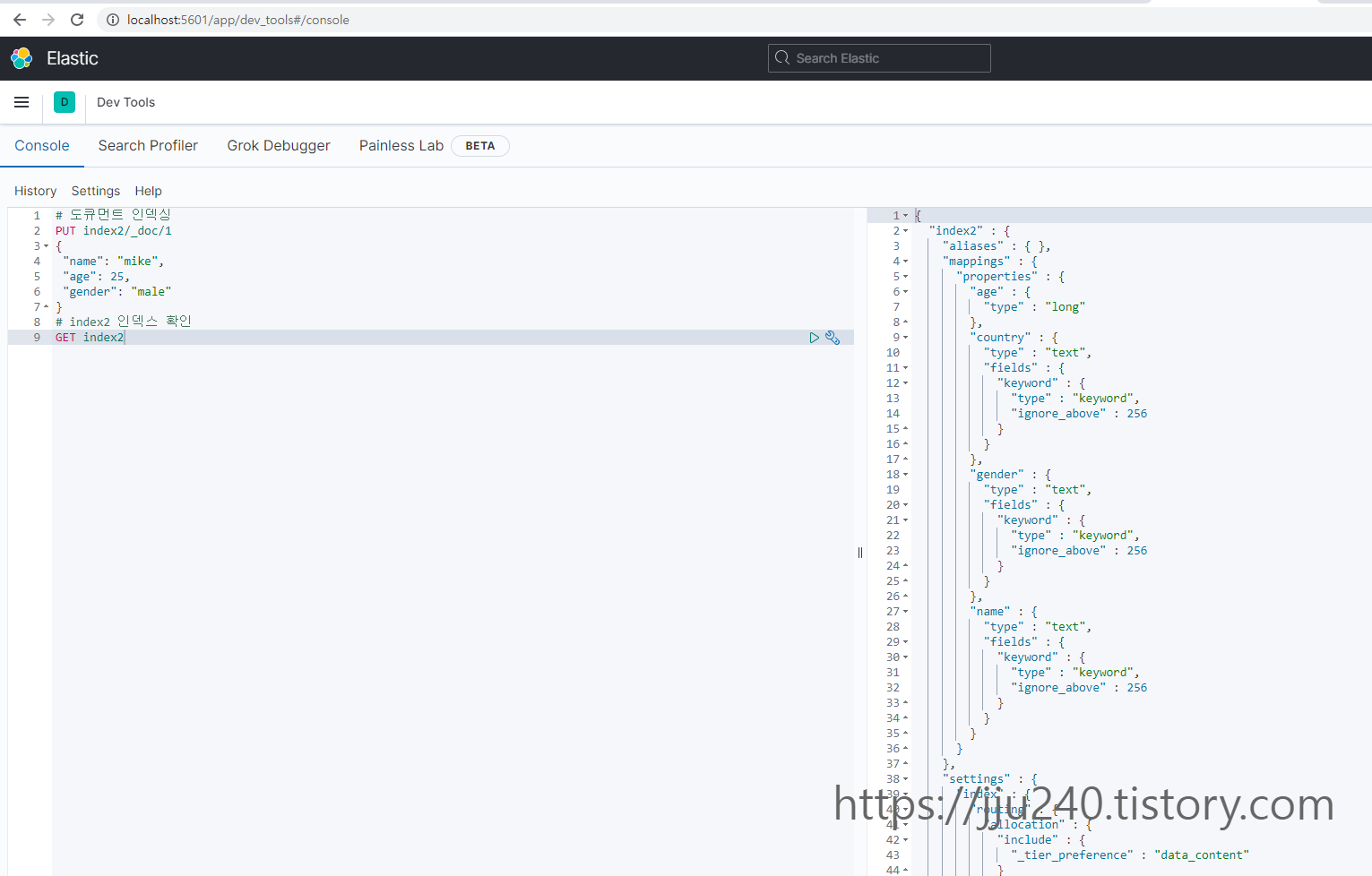
타입이 뭔지, 뭐 이런 거 정의 안 하고
다큐먼트를 저렇게 쓰면 들어간다.
숫자면 롱타입으로 들어가고
이름은 텍스트 타입으로 들어가고 등등 자동으로 들어가나 봄
신기하네~

3.3.3 도큐먼트 읽기
도큐먼트를 읽는 방법은 크게 도큐먼트 아이디를 이용해 조회하는 방법과
쿼리 DSL(Domain Specific Language)이라는 엘라스틱서치가 제공하는 쿼리문을 이용해 검색하는 방법이 있다.
• 4: 실제 빅데이터 세계에서는 도큐먼트를 하나씩 읽어오는 경우는 드물다.
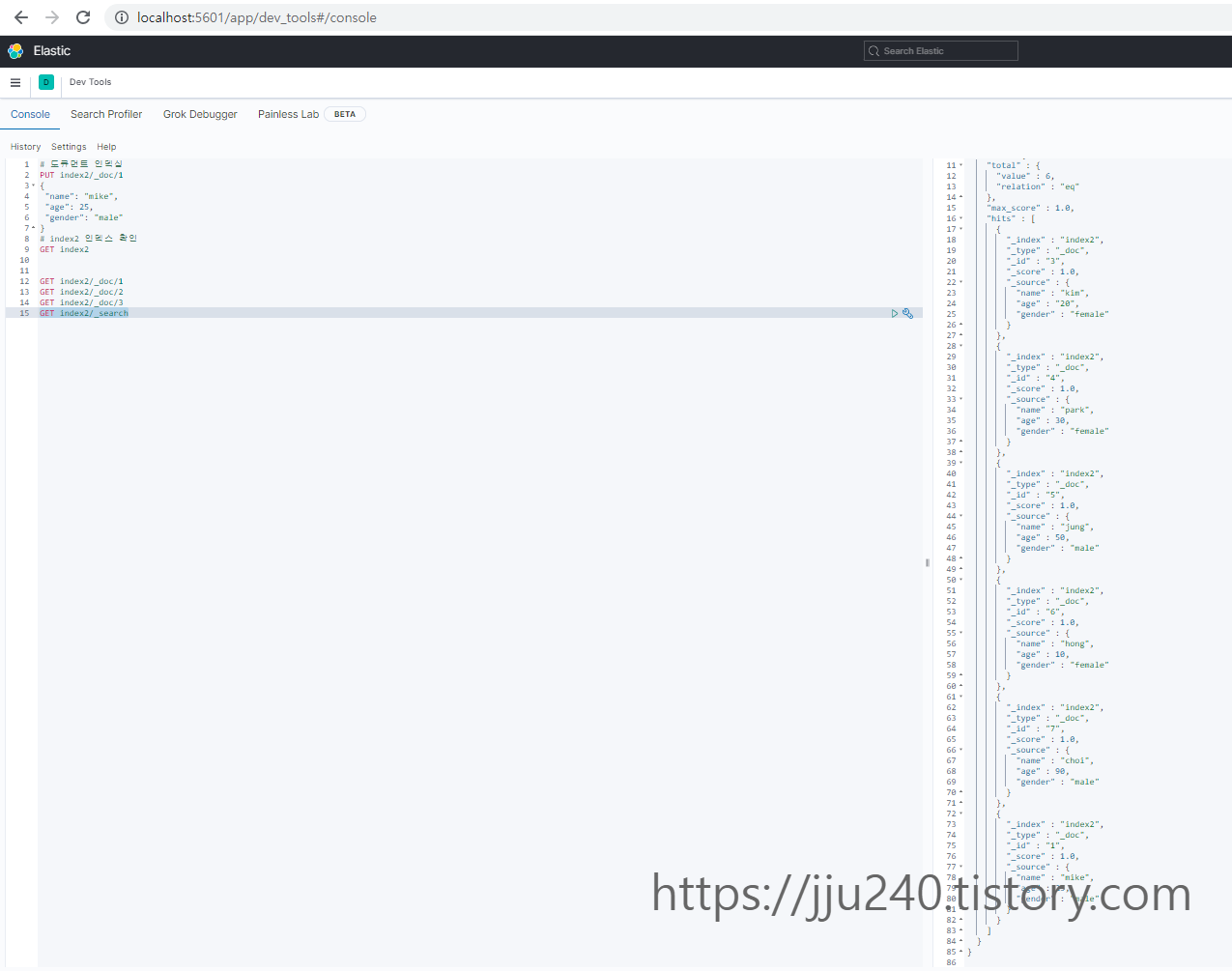
search라는 DSL 쿼리를 사용하면 index2 인덱스 내의 모든 도큐먼트를 가져온다.
3.3.4 도큐먼트 수정
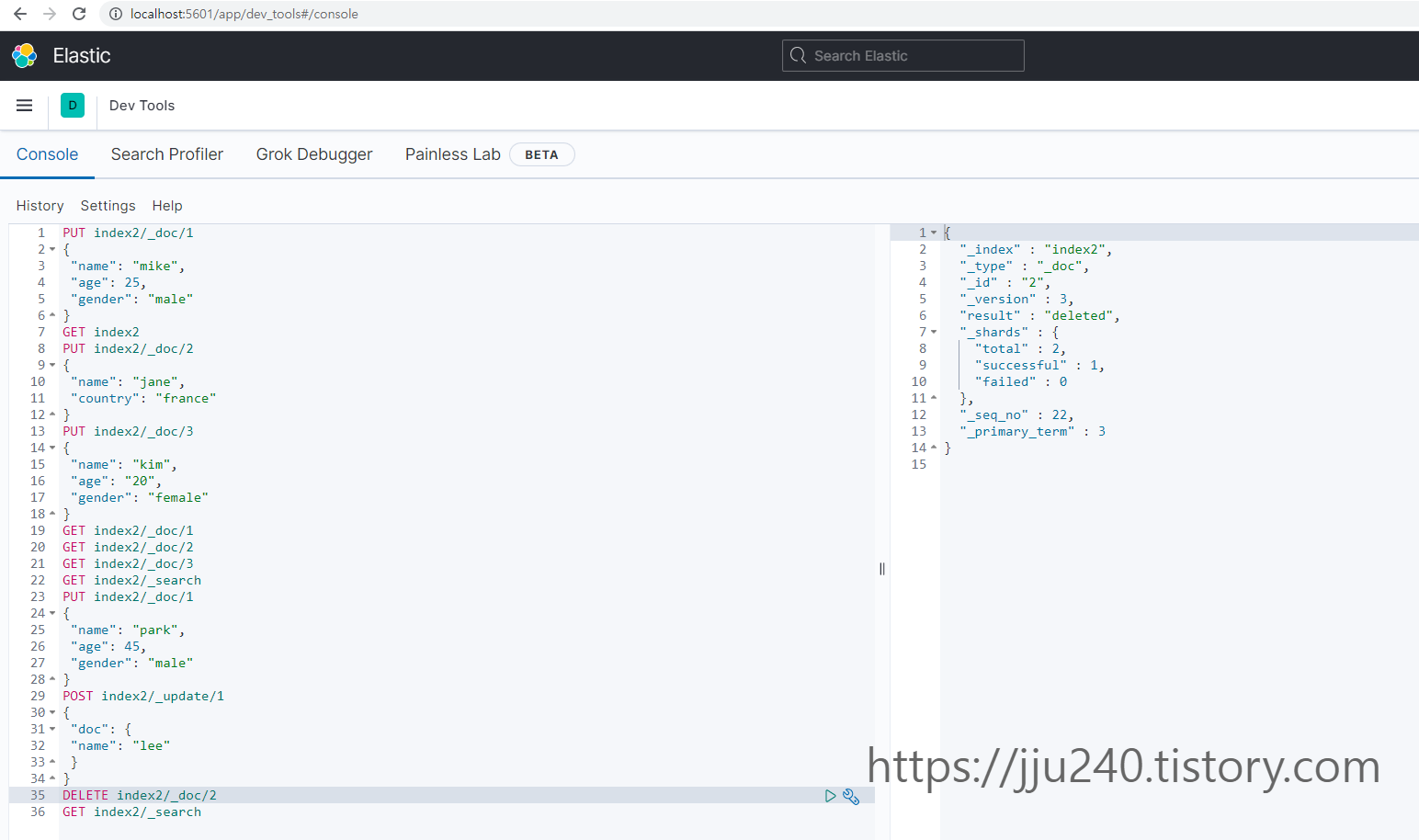
update API를 이용해 특정 도큐먼트의 값을 업데이트할 수 있다.
• 8: _update라는 엔드포인트(endpoint)를 추가해 특정 필드의 값만 업데이트할 수 있다.
엘라스틱서비 도큐먼트 수정 작업은 비용이 많이 들기 때문에 권장하지 않는다.
개별 도큐먼트 수정이 많은 작업이라면 엘라스틱서치가 아닌 다른 데이터베이스를 이용하는 것 이 좋다고 함.
3.3.5 도큐먼트 삭제
특정 도큐먼트를 삭제하기 위해서는 인덱스명과 도큐먼트 아이디를 알고 있어야 한다.
• index2 인덱스에서 아이디가 2인 도큐먼트가 삭제된다.
• index2 인덱스의 전체 도큐먼트를 확인한다.
3.4 응답 메시지
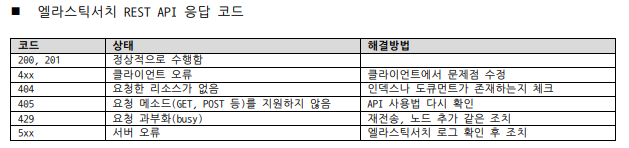
엘라스틱서치 REST API 응답 코드
3.5 벌크 데이터
데이터 CRUD 동작을 할 때는 REST API를 호출해 하나하나 도큐먼트를 요청하는 것보다
벌크(bulk)로 한 번에 요청하는 것이 효율적이다.
bulk API는 도큐먼트 읽기는 지원하지 않고 생성/수정/삭제만 지원한다.
• 삭제(delete)만 한 줄로 작성하고
나머지 작업(index, create, update)은 두 줄로 작성된다.
각 줄 사이에는 쉼표 등 별도의 구분자가 없고 라인 사이 공백(빈 줄)을 허용하지 않는다.

벌크 데이터를 파일 형태로 만들어서 적용하는 방법도 있다.
3.6 매핑
관계형 데이터베이스는 테이블을 만들 때 반드시 스키마 설계가 필요하다.
여기서 말하는 스키마는 테이블을 구성하는 구성요소 간의 논리적인 관계와 정의를 말한다.
엘라스틱서치도 관계형 데이터베이스의 스키마와 비슷한 역할을 하는 것이 있는데
바로 매핑(mapping)이다.
엘라스틱서치에서는 문자열을 텍스트(text)와 키워드(keyword) 타입으로 나눌 수 있는데,
전문 검색을 활용하려면 반드시 두 가지 타입을 이해하고 있어야 한다.
다이내믹 매핑, 명시적 매핑 이 두 가지 타입을 이해해야 한다.
3.6.1 다이내믹 매핑

3.6.2 명시적 매핑
인덱스 매핑을 직접 정의하는 것을 명시적 매핑(explicit mapping)이라고 한다.
인덱스를 생성할 때 mappings 정의를 설정하거나 mapping API를 이용해 매핑을 지정할 수 있다.
3.6.3 매핑 타입


참고도서 : 엘라스틱 스택 개발부터 운영까지
'주니어 기초 코딩공부 > 빅데이터 찍먹' 카테고리의 다른 글
| 캐글 CSV 파일을 활용한 인덱스 작성 (0) | 2023.06.07 |
|---|---|
| 05 엘라스틱 스택_키바나 소개_Visualize (0) | 2023.06.01 |
| 04 엘라스틱 스택_키바나 소개_discover (0) | 2023.06.01 |
| 03 엘라스틱서치: 검색 (0) | 2023.05.30 |
| 02 엘라스틱서치 기본 (0) | 2023.05.30 |